








Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista Científica de la UCSA
versión On-line ISSN 2409-8752
Rev. ciente. UCSA vol.1 no.1 Asunción dic. 2014
ARTICULO ORIGINAL
Automatización de previsión de demanda horaria de potencia eléctrica en el Sistema Interconectado Nacional
Hourly Load Forecast Automation in the National Interconnected System
*Barboza OA
Administración Nacional de Electricidad-ANDE, Asunción, Paraguay
RESUMEN
La operación electro-energética del SIN debe ser planificada para asegurar el suministro de energía con suficiencia técnica y bajos costos. Esta programación operativa debe considerar restricciones técnicas, como equipos en mantenimiento y generadores indisponibles, aspectos contractuales, etc., así como factores coyunturales como el clima y los feriados especiales, que inciden en el uso de la energía por parte de los diversos grupos de consumidores. En este sentido, la demanda de potencia global del país condiciona la contratación de potencia de las centrales hidroeléctricas, que constituye el principal componente del costo operativo de la ANDE. En este contexto, la operación eficiente del sistema de transmisión, desde el punto de vista técnico y económico, requiere de una estimación precisa de la potencia global demandada en la red, para cada hora de cada día (perfil de la demanda), así como de la consideración de determinadas restricciones, lo que hace necesario el uso de metodologías confiables para estimar dicha demanda y despachar la potencia adecuada desde cada central de generación. Este trabajo analiza las diversas metodologías aplicadas en el sector eléctrico para realizar pronósticos de demanda de corto plazo. Son aplicados abordajes estadísticos (ARIMA) y de Inteligencia Artificial (Red Neuronal Artificial: RNA) para realizar previsiones del perfil de demanda en el Sistema Interconectado Nacional, comparando posteriormente los resultados y analizando los errores de estimación. El modelo Auto Regresivo de Medias Móviles Integrado (ARIMA) es usado como benchmark, para complementar y dar un significado más consistente a las predicciones de la RNA. Los resultados de la investigación demuestran que la estimación del perfil de demanda del SIN puede automatizarse con aceptable precisión, suministrando así una herramienta más de apoyo a las decisiones de contratación de potencia de los agentes responsables y satisfaciendo las condiciones mínimas necesarias que proporcionan una garantía razonable para el adecuado despacho de carga.
Palabras clave: perfil de demanda, inteligencia artificial, Red Neuronal Artificial, ARIMA, despacho de carga.
ABSTRACT
The electric and energetic operation of the National Interconnected System should be planned to ensure the power supply with technical proficiency and low costs. This operational planning should consider technical constraints, such as equipment maintenance and generators unavailability, contractual issues and so on, as well as economic factors such as weather and holiday dates that affect the use of energy by various consumer groups. In this sense, the overall power demand of the country affects the hiring of hydroelectric power, which is the main component of the operating cost of ANDE. In this context, the efficient operation of the transmission system from the technical and economic terms, requires an accurate estimate of the demanded global power in the network, for each hour of each day (demand profile) and consideration of certain restrictions, making it necessary to use reliable methodologies for estimating such demand and dispatch the appropriate power from each power generation plant. This paper analyzes the various methodologies used for Short Term Load Forecast. They are applied a statistical approach (ARIMA) and artificial intelligence approach (Artificial Neural Network: ANN) for forecasting the load profile on the national grid, then comparing the results and analyzing estimation errors. Auto Regressive Integrated Moving Average Model (ARIMA) is used as a benchmark, to complement the predictions of the ANN method and make it stronger. The research results show that the estimation of the load profile of the National Interconnected System can be automated with acceptable accuracy, thus providing a tool for decision support power procurement officers responsible and meet the minimum requirements necessary to provide reasonable assurance suitable for load dispatch.
Keywords: Load Profile, Artificial Intelligence, Artificial Neural Network, ARIMA, Load Dispatch.
INTRODUCCIÓN
El pronóstico de la demanda de energía eléctrica se encuentra en el núcleo de varios procesos operacionales, incluyendo planificación, programación y control de la operación de sistemas de potencia. En el tradicional escenario centralizado, los sistemas de potencia son planeados, diseñados y operados como un todo, usando el pronóstico de la demanda de corto plazo (STLF: Short Term Load Forecast, por sus siglas en inglés) principalmente para garantizar la confiabilidad del suministro. En escenarios competitivos, pronósticos de demanda son usados por agentes comercializadores como una variable de referencia para el planteamiento de ofertas, además de ser de fundamental importancia en la determinación de los precios de energía eléctrica.
El objetivo de este trabajo es presentar una síntesis de los principales resultados de los estudios realizados para el desarrollo de un modelo computacional que permite predecir con aceptable precisión la demanda horaria de potencia eléctrica en el SIN.
Este trabajo analiza las particularidades de las series de demanda de potencia eléctrica en el SIN, la influencia de variables exógenas y la adecuación de diversas técnicas de predicción de uso extendido en el contexto de STLF. La herramienta seleccionada para la predicción del perfil de demanda diaria en el SIN es una técnica de inteligencia artificial de ampliamente utilizada en el sector eléctrico: Redes Neurales Artificiales (RNA).
Las RNA han recibido últimamente mucha atención en el ámbito de STLF y un gran número de artículos han reportado experimentos exitosos con ellas. Dada una muestra de vectores de entrada y de salida, las RNA son capaces de mapear automáticamente las relaciones entre ellos. Las RNA “aprenden” estas relaciones y almacenan este aprendizaje en sus parámetros. Puede probarse que las RNA son particularmente útiles cuando se posee una gran cantidad de datos, pero poco o ningún conocimiento previo acerca de las leyes que rigen el sistema que genera tales datos (1).
Asimismo, han sido empleadas técnicas estadísticas para validar los resultados de métodos prospectivos más sofisticados. El modelo ARIMA es un modelo univariante que utiliza variaciones y regresiones de series temporales, con el fin de encontrar patrones para una predicción futura. En el ámbito del pronóstico de la demanda de corto plazo, esta técnica es usada generalmente como referencia (benchmark), a efectos de verificar el desempeño de otros modelos de pronóstico de la demanda (2).
Las siguientes secciones describen los fundamentos teóricos de las series de demanda, del modelo ARIMA y de las RNA, la metodología aplicada y los resultados obtenidos, además de las conclusiones del estudio.
Previsión de demanda
El núcleo de la contratación económica de potencia lo constituye la estimación adecuada del perfil de la demanda. En este sentido, los modelos de pronóstico de demanda de corto plazo o STLF mencionados, pueden ser clasificados básicamente en dos categorías (3):
Abordajes estadísticos basados en series temporales: se distinguen métodos Univariantes (la demanda es modelada como una función de sus valores pasados observados) y Multivariantes (la demanda es modelada como una función de algunos factores exógenos, especialmente, variables climáticas y sociales). Los métodos Univariantes, como el ARIMA y modelos de Suavizado Exponencial, son usados actualmente como referencia, para propósitos de comparación. Modelos Multivariantes, empleando variables exógenas explicativas, a menudo denominados ARIMAX y modelos de funciones de transferencia lineal con transformaciones no lineales de las variables de entrada son necesarios para anticipar los efectos climáticos y aquellos asociados a las particularidades del calendario en los hábitos de consumo.
Abordajes basados en técnicas de inteligencia artificial: sistemas expertos, Redes Neurales Artificiales (RNA), lógica fuzzy y Máquinas de Soporte Vectorial (SVM: Supported Vector Machines, por sus siglas en inglés), son los principales paradigmas de inteligencia artificial aplicados al problema de pronóstico de demanda de corto plazo.
Desde la década de 1990, un gran número de investigaciones fueron dedicadas a la aplicación empírica de RNA al problema del pronóstico de demanda de corto plazo. Las ventajas de las redes neurales son su capacidad universal de aproximar numéricamente cualquier función continua, pero al mismo tiempo, adolecen la desventaja de correr el riesgo de sobre ajustar sus parámetros, lo que puede conducir a un pobre desempeño en las previsiones de demanda (4).
Particularidades de las series de demanda
Las series temporales de demanda son complejas y exhiben sendos niveles de estacionalidad: la demanda en una hora determinada depende no solo de la demanda en la hora previa, sino también de la demanda a la misma hora del día anterior y de la carga en la misma hora del día de la misma denominación de la semana previa. Las series de demanda muestran además tendencias, usualmente positiva o creciente, dinámicas de corto plazo, dependencia de eventos relacionados al calendario y efectos no lineales de variables meteorológicas. La tendencia en la demanda esta usualmente asociada a factores económicos y demográficos, mientras que las otras características están relacionadas con variaciones climáticas y del comportamiento humano.
Factores derivados de variables meteorológicas como la temperatura, radiación solar, humedad, velocidad del viento, nubosidad, duración de brillo solar o precipitaciones, han sido empleados como variables exógenas para mejorar el pronóstico de la demanda. Sin embargo, gran parte de las publicaciones usa solo la temperatura, debido a la indisponibilidad de registros confiables de mediciones de las demás variables.
ARIMA
En un modelo de series temporales univariante se puede descomponer la serie Yt en dos partes, una que recoge el patrón de regularidad, o parte sistemática, y otra parte puramente aleatoria, denominada también “innovación” La parte sistemática es la parte predecible con el conjunto de información que se utiliza para construir el modelo. La innovación es una parte aleatoria.
A la hora de construir un modelo estadístico, el problema consiste en formular la parte sistemática de manera que el elemento residual sea una innovación (ruido blanco). En el caso de los procesos estacionarios con distribución normal y media cero, la teoría de procesos estocásticos señala que, bajo condiciones muy generales, Yt se puede expresar como combinación lineal de los valores pasados infinitos de Y más una innovación ruido blanco, esta representación es puramente auto-regresiva (AR). El valor de Yt también se puede representar como la combinación lineal del ruido blanco y su pasado infinito, esta representación es puramente de medias móviles(MA).
Ambas representaciones son igualmente válidas para los procesos estocásticos estacionarios, es decir, procesos cuyas variables aleatorias tienen la misma media finita, tienen la misma varianza finita y las autocovarianzas solo dependen del número de periodos de separación entre las variables y no del tiempo. Estos procesos además deben ser no anticipantes e invertibles. El modelo finito donde el valor de Yt depende del pasado de Y hasta el momento t-p (parte auto-regresiva), de la innovación contemporánea y su pasado hasta el momento t-q (parte medias móviles), se denomina autorregresivo de Medias Móviles de orden (p;q), y se denota por ARMA (p;q).
Si un modelo ARMA, que representa el comportamiento de un proceso Yt, donde el polinomio autorregresivo posee “p-d” raíces con módulo fuera del círculo unidad y “d” raíces unitarias (proceso no estacionario), se denomina proceso integrado de orden “d”. Es decir, un proceso Yt, es integrado de orden d, I(d), si Yt no es estacionario pero su diferencia de orden d, ΔdYt sigue un proceso ARMA (p-d;q), estacionario e invertible. El orden de integración del proceso es el número de diferencias que se debe tomar al proceso para conseguir la estacionariedad en media. Este modelo se denomina modelo Autorregresivo Integrado de Medias Móviles de orden (p,d,q) o ARIMA (p;d;q), donde p es el orden del polinomio autorregresivo estacionario, d es el orden de integración de la serie, es decir, el número de diferencias que se debe tomar a la serie para que sea estacionaria, y q es el orden del polinomio de medias móviles invertible.
Redes Neurales Artificiales
La unidad básica de una RNA es la neurona artificial, que recibe información numérica a través de un cierto número de nodos de entrada, la procesa internamente y suministra una salida. El proceso es realizado en dos etapas. En primer lugar, los valores de entrada son combinados linealmente, luego, el resultado es usado como el argumento de una función de activación o transferencia no lineal. La combinación lineal emplea pesos, atributos de cada conexión y un término de umbral constante. Las RNA están compuestas de varias neuronas operando simultáneamente. Típicamente, una red es ajustada o entrenada de manera que, un conjunto particular de entradas, origine una salida específica (objetivo). Es decir, los pesos que unen los diversos nodos de una RNA y los umbrales de cada neurona son ajustados comparando la salida de la red con la salida objetivo, hasta que ambas salidas sean prácticamente iguales.
La manera en que las neuronas son organizadas define la Arquitectura de la red. Una de las arquitecturas más empleadas para los pronósticos de demanda de corto plazo es la del tipo Perceptrón Multicapa (MLP, por sus siglas en inglés: Multil-Layer Perceptron), en que las neuronas son organizadas en capas. Las neuronas en cada capa pueden compartir las mismas entradas, pero no están conectadas unas con otras en la misma capa. Si la estructura es con alimentación hacia delante (feed-forward) las salidas de una capa son usadas como las entradas de la capa siguiente. Las capas entre los nodos de entrada y la capa de salida son llamadas capas ocultas. En aplicaciones de pronóstico de la demanda, esta forma básica de arquitectura multicapa con alimentación hacia delante continua siendo la arquitectura más popular en la actualidad (2).
Los parámetros de este tipo de redes son la matriz de pesos y el vector de umbrales. La estimación de los parámetros es conocida como “entrenamiento” de la red, y es hecha por la minimización de una determinada función (usualmente, una función cuadrática del error de salida). El primer algoritmo de entrenamiento que fue ideado es el de “propagación hacia atrás” (back-propagation) que usa una técnica de reducción por pasos basado en el cálculo del gradiente de una función de desempeño respecto a los parámetros de la red.
Metodologia aplicada
Existen muchos reportes de aplicaciones exitosas de RNA, particularmente en el campo de reconocimiento y clasificación de patrones. Considerando que los pronósticos cuantitativos están basados en la extracción de patrones de eventos observados y la extrapolación de estos patrones a eventos futuros, puede esperarse que las RNA sean buenas candidatas para realizar esta tarea. Esta idea es apoyada por al menos dos razones: primero, las RNA son capaces de aproximar numéricamente cualquier función continua, con la precisión deseada. En segundo lugar, las RNA son métodos donde los resultados y las conclusiones son obtenidos a partir de los datos. En este sentido, no es necesario postular modelos tentativos y luego estimar sus parámetros.
Con vistas a automatizar la previsión de demanda en el SIN, fueron desarrolladas y probadas varias RNA. Los datos de demanda horaria correspondientes a los años 2011 y 2012 fueron empleados para el efecto, considerando los valores de demanda de potencia del SIN de cada hora del día como series temporales distintas, es decir, se consideraron 24 series, para las cuales fueron desarrolladas 24 RNA respectivamente. Por tanto, la predicción de cada hora es independiente. Se procedió de esta manera debido a que con ello, cada RNA resultante tiene menor cantidad de parámetros (en relación a una sola RNA con 24 nodos de salida), con lo que el riesgo de sobre ajustar los mismos disminuye, logrando predicciones de mayor precisión (4).
Pre-procesamiento de datos
El factor más importante para determinar la forma del perfil de la demanda es el calendario. Los perfiles de los días laborales de la semana usualmente difieren en gran medida de los correspondientes a los fines de semana y feriados. Así, la clasificación básica se realizó mediante un código binario, en tres tipos de días: días de entresemana (lunes a viernes), sábados, y domingos y feriados.
El segundo factor en importancia que afecta el perfil de la demanda es el clima. Como principal variable climática, en este trabajo fue empleada la temperatura diaria máxima ponderada, considerando las mediciones realizadas en las estaciones meteorológicas de Asunción, Ciudad del Este, Villarrica, Encarnación y Concepción, representativas respectivamente, de los Sistemas Metropolitano, Este, Central, Sur y Norte-Oeste.
Por otro lado, y a efectos de caracterizar en cierto modo la estacionalidad anual de las series de demanda, cada mes del año fue representado por su Humedad Relativa media mensual, Velocidad del Viento media mensual y Precipitación media mensual.
Diseño de la RNA
La arquitectura de RNA seleccionada en este trabajo es la denominada Perceptrón Multicapa (MLP), con alimentación hacia delante, completamente conectada. Se procedió así debido a que este trabajo constituye un esfuerzo pionero de aplicación de RNA a la previsión de demanda en Paraguay y considerando que dicha arquitectura es la de uso más extendido en el contexto de STLF. Para la implementación de las RNA se recurrió a la plataforma MatLab® Neural Network ToolboxTM.
Ha sido demostrado que una sola capa oculta es suficiente para aproximar cualquier función continua (3), por lo que las RNA correspondientes a cada una de las 24 horas del día, usadas en este trabajo, poseen una sola capa oculta. La función de activación (transferencia) de cada una de las neuronas de la capa oculta es la función Tangente Hiperbólica Sigmoidea, mientras que la función de activación de la única neurona de la capa de salida (pronóstico multimodelo, 24 RNA en paralelo) es una función lineal.
En cuanto a la cantidad de neuronas de la capa oculta, las mismas fueron establecidas en base a simulaciones y ensayos de prueba y error, tomándose el promedio de los errores cuadráticos medios de cada configuración en 30 simulaciones con condiciones iniciales diferentes, a efectos de obtener un modelo robusto para cada hora.
Cada RNA correspondiente a cada hora del día, tiene 13 entradas. Para emular las condiciones y los datos disponibles al momento de hacer la predicción de demanda del día siguiente en el Despacho de Carga de la ANDE, se consideran como entradas las demandas de la misma hora del día anterior y las demandas de 5 horas antes en ese día. Otra entrada es la demanda de la misma hora del día de la misma denominación en la semana anterior. Por su parte, la clasificación del tipo de día (entresemana, sábados, domingos y feriados) ocupa dos entradas (código binario), mientras que la temperatura máxima ponderada del día y la caracterización del mes (Humedad Relativa, Velocidad del Viento y Precipitación medias mensuales) ocupan las cuatro entradas restantes.
Implementación de la RNA
El algoritmo de entrenamiento seleccionado para el ajuste de los parámetros de las RNA es el Algoritmo de propagación hacia atrás (Backpropagation, implementado en MatLab® mediante el algoritmo de Levenberg-Marquardt), que es una generalización de la regla de aprendizaje de Widrow-Hoff aplicada a las redes multicapa con funciones de transferencia no lineales diferenciables. Este es un algoritmo gradiente - descendente, en que los parámetros de la red son ajustados en la dirección negativa del gradiente de la función de desempeño (performance) de la RNA, que es la función de Error Cuadrático Medio (MSE: Mean Square Error, por sus siglas en ingles).
Para evitar el problema de la sobreparametrización (overfitting) y lograr un desempeño adecuado, durante el entrenamiento son empleados dos recursos (4): validación cruzada (cross-validation) y detención temprana (early stopping).
La validación cruzada separa aleatoriamente los vectores de entrada con sus correspondientes salidas en tres grupos: entrenamiento (60 %), validación (20 %) y prueba (20 %). Realiza el ajuste de parámetros con el conjunto de entrenamiento, monitoreando el MSE de los pronósticos en el conjunto de validación y dejando el conjunto de prueba para verificar la precisión de la red en un conjunto de datos que no es visible a la RNA durante su entrenamiento. Por su parte, la detención temprana verifica el error en la muestra de validación a cada iteración de ajuste en la muestra de entrenamiento, cuando dicho error se incrementa por determinado número de iteraciones, el entrenamiento se detiene.
Validación de la RNA
La teoría plantea que la validación de un modelo de RNA ha sido adecuadamente realizada si: a) su desempeño fue comparado con el desempeño de métodos de previsión aceptados (ARIMA, ARMAX, métodos de regresión); b) la comparación ha sido realizada en muestras de prueba (diferentes a la de entrenamiento) y c) el tamaño de las muestras de prueba es adecuado, de manera que algunas inferencias pueden ser esbozadas.
En este trabajo, se emplea el modelo ARIMA para comparación de los datos, correspondientes a la muestra de prueba, definida durante la fase de entrenamiento. Las funciones MAPE y MSE son usadas para verificar la precisión de las predicciones de la RNA.
En el contexto de STLF, las medidas de precisión más populares son el Error Absoluto Medio Porcentual (MAPE, por sus siglas en inglés: Mean Absolute Percentage Error), así como el MSE. El MAPE captura la proporcionalidad entre el error de predicción absoluto y la demanda real, permitiendo una interpretación sencilla, lo que lo posiciona en el sector eléctrico como un estándar de medida de precisión en STLF. Valores típicos de MAPE para predicciones de perfiles de demanda (próximas 24 horas) se encuentran entre el 1 y 4 % (2,3). Se calcula mediante la siguiente fórmula:
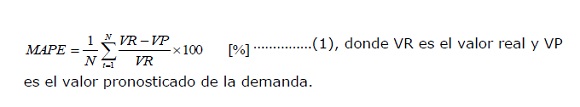
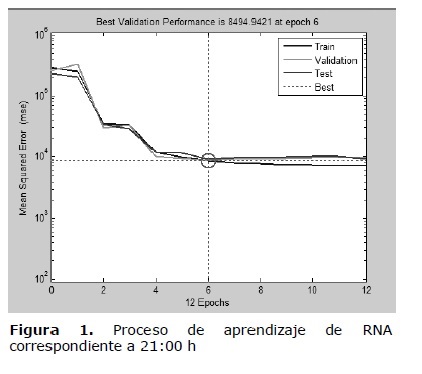
Las predicciones del perfil de demanda diaria del SIN mediante RNA, correspondientes a valores registrados entre los años 2011 y 2012, mostraron precisión aceptable en relación con los resultados encontrados. La figura siguiente muestra el MSE de la red correspondiente a las 21:00 horas (hora critica en relación a la previsión, ya que en torno a ella se produce la demanda máxima simultanea del SIN) en función al número de iteraciones del proceso de entrenamiento (epoch). Puede verse que inicialmente el MSE es elevado y va decayendo. Luego de algunas iteraciones el MSE es prácticamente constante, es decir, la figura 1 muestra el proceso de aprendizaje de la RNA. Los resultados son auspiciosos, ya que el menor MSE ocurre prácticamente en la misma iteración para los conjuntos de Validación y Prueba, caso contrario, puede asumirse un pobre desempeño de la RNA.
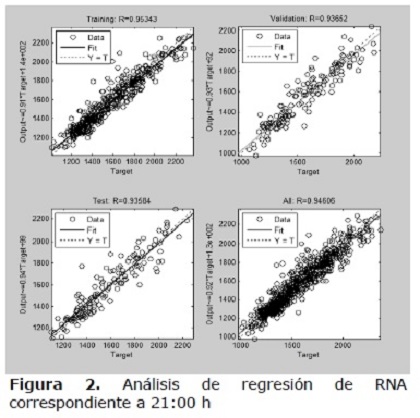
Por su parte, la Figura 2 muestra un breve análisis de regresión entre las salidas de la RNA correspondiente a las 21:00 horas y los valores registrados. Las salidas siguen adecuadamente los valores registrados para los conjuntos de entrenamiento, validación y prueba y los valores del coeficiente de correlación R se encuentra ligeramente por debajo de 0,95 para el total de las predicciones.
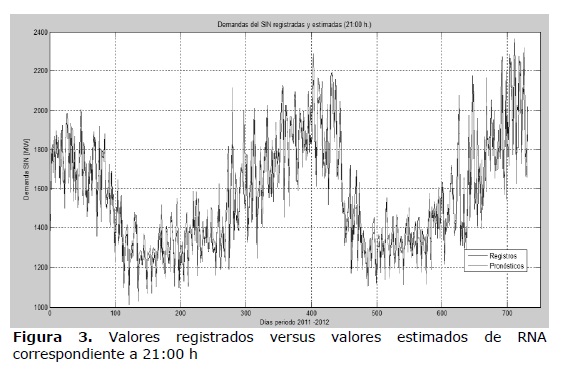
La Figura 3 proporciona una visión global de la precisión de las predicciones de la misma RNA considerada en las figuras precedentes, graficando los valores de demanda registrados versus los valores pronosticados por la RNA a lo largo del periodo 2011-2012 (731 días).
Finalmente, cabe resaltar que el MAPE calculado con la ecuación (1) correspondiente a las muestras de prueba (146 días, 3504 horas), obtenido mediante las 24 RNA operando en paralelo fue de 1,35 %, mientras que el MAPE obtenido mediante el modelo ARIMA (1; 1; 2) fue de 3,84 %.
CONCLUSIÓN
Los resultados obtenidos en el presente trabajo señalan que las RNA proporcionan una plataforma adecuada para la automatización de la demanda de potencia eléctrica en el SIN. La precisión de las predicciones se encuentra dentro de los márgenes reportados.
A diferencia de los modelos estadísticos, las RNA pueden responder con gran flexibilidad a cambios considerables en el patrón de comportamiento de los consumidores, por lo que pueden adaptarse con mayor facilidad a modificaciones estructurales en el mercado de energía eléctrica.
La aplicación efectiva de la metodología aquí propuesta para la predicción de la demanda horaria del SIN como insumo fundamental para la programación de la operación electro energética de la red eléctrica del Paraguay está sujeta a criterios operativos relacionados con la precisión requerida, así como a potenciales mejoras en el modelo sugerido, explorando diferentes variables climatológicas, aumentando la cantidad de datos usados para entrenar las RNA o inclusive, modificando la arquitectura de la red aquí presentada.
REFERENCIAS BIBLIOGRÁFICAS
Bansal, R.C.& Pandey, J.C.(2005).“Load forecasting using artificial intelligence techniques: a literature survey”. Int J Comput Appl Technol, 22(2-3),109-9.
Soares, L.J. & Medeiros MC. (2008). “Modeling and forecasting short-term electricity load: a comparison of methods with a application to Brazilian data”. Int. J Forecast, 24, 630-44.
Taylor, J.W. & McSharry, P.E. (2008). “Short-term load forecasting methods: an evaluation based on european data”.IEEE Trans Power Syst, 22, 2213-6.
Hippert, H.S., Bunn, D.W. & Souza, R.C. (2005). “Large neural networks for electricity load forecasting: are they overfitted?.” Int. J Forecast, 21(3), 425-34.
*Autor Correspondiente: Oscar Barboza. Administración Nacional de Electricidad-ANDE. Asunción, Paraguay
E-mail: oscar_barboza@ande.gov.py
Fecha de recepción: setiembre 2014; Fecha de aceptación: noviembre 2014