









 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
En la actualidad, en el campo de la telemática aplicada a la Educación Musical, en concreto en Educación Secundaria, se encuentran multitud de herramientas que presentan cada vez un mayor grado de implantación en la tecnología educativa y que, gracias a sus prestaciones, ofrecen la posibilidad de obtener un elevado nivel de control del proceso de enseñanza-aprendizaje del alumnado y todas sus variables en el marco de inclusión de las Tecnologías de la Información y la Comunicación (TIC, en adelante) en instituciones educativas (Oliveira, 2014).
En esta experiencia de investigación musical, se emplea una plataforma de teleformación denominada Moodle.1 Moodle es el acrónimo de Modular Object Oriented Dynamic Learning Environment, un software usado cada día con más frecuencia en educación (Montgomery et. al., 2015). Es un proyecto desarrollado para su libre distribución y para apoyar el constructivismo social dentro del marco educativo.
Como objetivo de este estudio se marca el demostrar la utilidad de las técnicas procedentes del Big Data, para el análisis de datos educativos musicales en cursos masivos en línea. En concreto, se tienen en cuenta los datos referidos a las evaluaciones iniciales que el alumnado realiza a principios de curso.
Las ventajas de Moodle han sido ampliamente estudiadas. Aydin y Tirkes (2010), Kop (2011) y Kearney y Levine (2015) destacan que apoya la pedagogía social constructivista (colaboración, actividades de aprendizaje, reflexión crítica, etc.), es apropiada la educación presencial y a distancia, fácil de instalar en la mayoría de las plataformas (incluidos smartphones o tabletas), de fácil administración en el entorno de la Web 2.0 (el alumnado puede crear sus propias cuentas, un perfil en línea incluyendo sus fotos y su descripción, intereses, gustos y motivaciones, elegir el formato del curso por semana, por tema o por tema de discusión basado en un formato social que potencia la comunicación y el intercambio de información en procesos de enseñanza-aprendizaje musical), etc.
Por otro lado, desde la usabilidad de las técnicas del Big Data, campo que supone el uso de modelos estadísticos a partir de grandes volúmenes de información (como los que se generan hoy en día con los cursos masivos en línea, los llamados MOOC, en inglés MOOCs, Masive Open Online Courses), aporta importante información y muy detallada sobre el funcionamiento de los agentes educativos intervinientes (participación de padres, madres, profesorado, alumnado e instituciones educativas) y de los objetos de aprendizaje (herramientas de comunicación como chats, foros, test de autoevaluación y actividades colaborativas) y de las plataformas de teleformación o sistemas de gestión virtual de los aprendizajes (LMS o learning management systems) (Santos y Carvalho, 2014).
Así, la aplicación de las técnicas del Big Data en la plataforma telemática Moodle para el aprendizaje musical virtual, permite obtener los perfiles de los usuarios y otra información sobre los agentes del proceso y prepara el terreno para una adecuada educación personalizada (Calderero, Aguirre, Castellanos, Peris y Perochena, 2014). Este modelo de trabajo tiene múltiples ventajas, si bien las más destacables están en la capacidad de poder gestionar la totalidad de los datos registrados sobre aprendizaje y establecer perfiles del alumnado mediante pruebas de diagnóstico o evaluaciones iniciales, realizadas al principio del curso académico por parte de todos los centros educativos (Oliveira, 2014).
El hecho de atender a la educación personalizada supone, desde el principio del proceso de enseñanza-aprendizaje atender a los intereses y motivaciones del alumnado. Teniendo, de esta forma, en cuenta las características individuales de cada uno de ellos, monitorizando su trabajo y orientando toda de su labor de forma correcta.
La educación personalizada ha sido y es, probablemente, uno de los más importantes retos de la educación. Las TIC no han hecho más que dar un nuevo impulso a este deseo de responder a las personas en sus procesos educativos (Calderero, Aguirre, Castellanos, Peris y Perochena, 2014), algo que no va en contradicción con la atención a los grupos o a la comunidad (Sandler, 2012), sino que, por el contrario, esta manera de ver la educación personalizada contribuye a la posibilidad de atención a los grupos de forma eficaz (RAND Corporation, 2014; Redding, 2014a, 2014b y 2014c).
Por otro lado, la educación personalizada aúna factores como la socialización y la individualización educativas y constituye el tipo de educación más apropiada para la sociedad digital en la que estamos inmersos (Sadovaya, Korshunova y Nauruzbay, 2016). Además, potencia la adquisición de las competencias (Twyman, 2014) de forma que nos encaminemos de manera libre y responsable hacia el control de nuestras propias vidas, el desarrollo de la autonomía personal y el autoaprendizaje.
En relación a las técnicas de análisis empleadas para el análisis de la información educativa recogida, se aplica el denominado modelo bietápico, que agrupa conjuntos de datos en grupos distintos o conglomerados (Yin, 2009; Santos y Carvalho, 2014).
Este método define un número fijo de conglomerados, de forma iterativa asigna registros a los conglomerados y ajusta los centros de los conglomerados hasta que no se pueda mejorar el modelo (Bryk y Raudenbush, 2002). Los modelos bietápicos utilizan un proceso conocido como aprendizaje no supervisado para revelar los patrones del conjunto de campos de entrada. Según Irigoien y Arenas (2006: 261) el análisis cluster o clustering “es una colección de métodos estadísticos que permiten agrupar casos sobre los cuales se miden variables o características”.
En investigación, el clasificar objetos es una necesidad y algo muy habitual, ya que permite ordenar y agrupar para conocer las categorías en las que se puede constituir la propia realidad o los objetos estudiados. Los clusters o grupos que se forman a través del análisis bietápico, tienen la peculiaridad de basarse en que no contamos con información previa y se sugieren a partir de la propia esencia de los datos (Bryk y Raudenbush, 2002). Para la elaboración de modelos tipo cluster existen una gran cantidad de técnicas, algunas de ellas muy complejas.
El modelo bietápico tipo cluster empleado supone un análisis de conglomerados. Dicho cluster se construye en dos etapas y está pensado para trabajar con grandes masas de datos (Big Data), es decir para estudios con un número de sujetos grande que pueden tener problemas de clasificación con otras técnicas de clasificación. Se puede utilizar cuando el número de grupos es conocido a priori y también cuando es desconocido. Por otro lado, posibilita el trabajo de manera conjunta con variables de tipo mixto (cualitativas y cuantitativas).
Este estudio expone un método simplificado para el trabajo del profesorado con esta técnica estadística, permitiendo manejar un gran volumen de datos en tiempo real y organizar en categorías o grupos dicha información para después ser sometida a estudio y tomar decisiones educativas (Murillo, 2008).
Así pues, el modelo bietápico supone una solución ideal, fácil y sencilla de utilizar en las plataformas educativas, en el marco de los cursos masivos en línea (Kay, Reimann, Diebold y Kummerfeld, 2013), gracias a sus posibilidades de automatización y configuración, siendo un método eficaz y eficiente para el conocimiento de los perfiles del alumnado (alto, medio, bajo), así como otras funcionalidades (Santos y Carvalho, 2014).
A partir de su aplicación, se pueden conocer de forma precisa sus niveles de conocimientos musicales previos, algo de gran utilidad para la aplicación de programas posteriores de educación personalizada, usados éstos de forma rigurosa y objetiva, mediante el análisis de los datos obtenidos a partir de las pruebas de evaluación inicial. Gracias al algoritmo bietápico empleado, que conecta directamente con las bases de datos de la plataforma de aprendizaje y permite ser programado para recibir información actualizada y en tiempo real de los niveles de conocimientos musicales del alumnado, las posteriores intervenciones en los procesos de enseñanza-aprendizaje aumentan su sentido y funcionalidad.
METODOLOGÍA
La muestra del estudio en el que han participado 10 centros educativos distintos de la provincia de Sevilla (España), es de 741 estudiantes de primer curso de Educación Secundaria Obligatoria con edades comprendidas entre los 12 y 13 años.
Los instrumentos empleados para la elaboración de este estudio son una plataforma telemática Moodle alojada en un servidor informático y el software de modelización estadística Clementine, en su versión 11.1.
En este estudio sobre la eficiencia y utilidad del uso de las técnicas del Big Data en los procesos de enseñanza-aprendizaje musical mediados por los MOOC, 10 centros de la provincia de Sevilla (n=10) fueron invitados a participar de forma totalmente confidencial y anónima. La invitación fue cursada mediante el uso del correo electrónico de los diferentes centros educativos y los centros seleccionados de forma aleatoria.
El test ha consistido en 7 preguntas para medir el nivel de conocimientos del alumnado de 1º de Educación Secundaria Obligatoria, alumnado que tiene edades comprendidas entre 12 y 13 años. Las preguntas específicas del test aparecen en el anexo de este trabajo y pueden ser consultadas. Las cuestiones abordan diferentes bloques temáticos como fundamentos del lenguaje musical, diferenciación entre signos musicales, clasificación de instrumentos musicales, distinción entre sonidos en diferentes claves musicales o audición musical.
Los datos fueron recogidos durante los dos primeros meses del curso 2014-2015. En concreto se estudian las pruebas de diagnóstico iniciales, realizadas a comienzo del curso académico con el objetivo de medir el nivel de conocimientos musicales previos del alumnado. Este test ha sido respondido de forma totalmente confidencial y anónima a través de la modalidad online. Las escuelas que han participado en el estudio han sido elegidas de forma aleatoria y a través del correo electrónico, a las mismas se les ha solicitado la participación en la investigación.
RESULTADOS
Para el análisis de los datos se ha empleado el programa SPSS Clementine 11.1, programa especializado en el análisis de grandes volúmenes de datos (mediante técnicas del Big Data) y la elaboración de modelos estadísticos. Dicho software fue conectado a la base de datos de la plataforma telemática Moodle, lo que permitió la monitorización de los test y la obtención de informes detallados sobre la realización del mismo. Hemos elaborado un proyecto de minería de datos y esto nos ha permitido automatizar tareas de análisis como la obtención de información y la exportación de resultados al sistema utilizado para trabajar, la plataforma de teleformación Moodle y su base de datos.
Los análisis se basaron en una metodología con tres partes perfectamente delimitadas. En primer lugar, cuando trabajamos con técnicas del Big Data se somete a los datos a una limpieza y selección de la información. En concreto, se seleccionan las variables o variable objeto de estudio, en concreto las puntuaciones de los test de evaluación inicial y eliminamos los valores nulos, que no sirven para la obtención del modelo tipo cluster. A continuación, en una segunda fase se aplica la técnica del bietápico y se selecciona el número de conglomerados que queremos obtener. Al dividir los grupos del alumnado en tres niveles de conocimientos previos (alto, medio y bajo), el número de clusters que seleccionamos es 3. De esta forma el espacio de cada conglomerado aparecerá delimitado por este criterio de clasificación y mostrará un índice de distancia con respecto al centroide o el valor en torno al cual se van agrupar los datos de cada grupo (como veremos en la gráfica más adelante). En tercer, para esclarecer y comprender mejor el modelo obtenido se presentan en una gráfica los tres conglomerados obtenidos y agrupados por el algoritmo informático bietápico empleado. A continuación, se desglosan cada uno de estos tres apartados de limpieza, selección, elaboración del modelo y visualización.
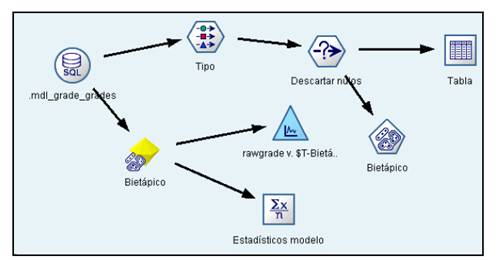
La siguiente imagen (Figura 1) muestra, de forma general, el proyecto de minería de datos o Big Data elaborado para la obtención del modelo bietápico en este estudio. Se observa la posibilidad de programar de forma gráfica, algoritmos que permiten la automatización de los procesos de análisis. Los datos se pueden particionar, algo interesante sobre todo cuando se manejan grandes volúmenes de información, registros y variables, e incluso emplear técnicas de muestreo con datos escogidos de forma aleatoria y entrenar el modelo para que sea lo más preciso posible. Una vez entrenado el modelo, podría aplicarse al total de la muestra y de forma automática y en tiempo real obtener los resultados de los análisis a partir de los datos de la base de datos de la aplicación informática que se utiliza para la recogida de la información.
Tras observar cómo sería un proyecto de minería de datos se muestra una tabla (Figura 2) con los estadísticos básicos y la distribución de la muestra. La tabla muestra un recuento de registros válidos de 741 en total, es decir que dicho número se corresponde con los alumnos y alumnas identificados con un "id", es decir, un número identificador único que se vincula con su nombre y datos personales de la base de datos del sistema, que permite conocer en todo momento de qué alumnos estamos hablando y monitorizar su trabajo, así como hacer el seguimiento de su proceso de enseñanza-aprendizaje.
La media de las puntuaciones de los test de evaluación inicial para medir el nivel de conocimientos musicales previos es 79,032 en una escala de 0 a 100. El mínimo es 0 y el máximo 100. La varianza 380,128 y la desviación típica 19,497.
La mediana 80,000 y la moda 100.
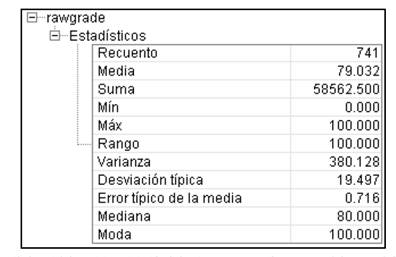
Figura 2. Estadísticos básicos del modelo bietápico (recuento, media, suma, mínimo y máximo, mediana y moda, entre otros).
A continuación, se muestra la elaboración del modelo bietápico paso a paso y las imágenes de la configuración del modelo y los resultados obtenidos.
En la elaboración del modelo bietápico se observan algunos datos significativos como el número de conglomerados obtenidos que han sido 3, que establecen los perfiles alto, medio y bajo de nivel de conocimientos previos. Estos datos se obtienen a partir de las puntuaciones obtenidas en la realización del test online para medir el dicho nivel a través de las evaluaciones iniciales, efectuadas a principios de curso.
Por otro lado, se refleja el tiempo invertido para la obtención del modelo. El procesamiento de la información de los tests es de 0 horas, 0 minutos y 4 segundos, como se observa al final de la figura siguiente (Figura 3). El tiempo total, invertido para la elaboración del modelo bietápico, óptimo, fiable y definitivo, depende de la reducción del margen de error del modelo, a través de un algoritmo informático que va haciendo iteraciones, hasta que el valor de los datos de salida sean 0,0 tal y como se observa en la siguiente tabla.

Figura 3. Resumen del modelo bietápico (número de iteraciones, particiones y tiempo para la generación del modelo).
En el siguiente modelo se pueden ver 3 bloques, conglomerados o clusters. Cada uno de estos clusters presenta niveles de conocimientos musicales previos, obtenidos a partir de las evaluaciones iniciales:
El conglomerado 1 presenta una muestra de 315 registros. La media es 96,893 en una escala de 0 a 100. La desviación típica es de 3,874. Este cluster aparece definido por el grupo formado por un alumnado con un nivel alto de conocimientos musicales previos.
El conglomerado 2 refleja una muestra de 321 registros. La media es 72,761 en una escala de 0 a 100. La desviación típica es 7,414. El cluster 2 representa al alumnado con un nivel medio de conocimientos musicales previos.
El conglomerado 3 arroja un total de 105 registros. La media es 44,619 en una escala de 0 a 100. La desviación típica es 14,389. El índice de proximidad del con respecto al cluster 1 es 0,28857 y el cluster 2 0,417038. El cluster 3 representa al alumnado con un nivel bajo de conocimientos musicales previos.

Figura. Modelo bietápico generado (medias, recuento de registros, desviación típica e índices de proximidad).
Seguidamente se presenta el modelo bietápico de forma gráfica (Figura 4), con un alto grado de fiabilidad y que arroja como valor 1,00. También se observa el gráfico de sectores y de barras la distribución de la muestra del modelo expuesto con los conglomerados que establecen los niveles de conocimientos musicales previos.

Figura 4. Modelo bietápico generado que representa la alta fiabilidad del modelo obtenido y las gráficas de sectores y barras con la distribución de la muestra en los niveles de conocimientos previos: alto, medio y bajo.
Posteriormente, aparece la gráfica (Figura 5) con el modelo correspondiente a las puntuaciones obtenidas y los diferentes conglomerados. En la imagen se muestra con claridad los tres niveles que planteamos en nuestro marco teórico: alto, medio y bajo. Dichos niveles serán los niveles de conocimientos previos del alumnado que participa de forma anónima en el estudio.
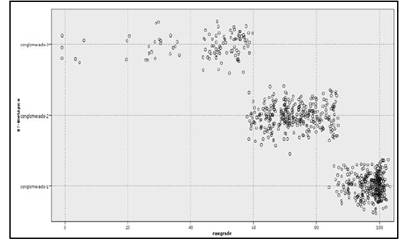
Figura 5. Modelo bietápico obtenido con los tres niveles de conocimientos previos del alumnado: alto, medio y bajo, obtenidos a partir de los test de evaluación inicial.
CONCLUSIONES
Los resultados que se obtienen en el siguiente artículo son:
En primer lugar, mediante las técnicas del Big Data aplicadas al ámbito educativo se pueden monitorizar y establecer niveles de aprendizaje musical. En concreto, en nuestro estudio el Modelo bietápico permite delimitar un nivel de conocimientos musicales altos, medios y bajos. Esto posibilita potenciar la educación personalizada en la escuela y atender a la diversidad educativa en el aula de forma útil y eficaz. Los clusters o agrupamientos obtenidos (según los niveles establecidos a partir de las puntuaciones del test de evaluación), muestran un alto índice de alumnado (cantidad de alumnos y alumnas) con un nivel de conocimientos musicales previos (cluster 1 y 2) y un bajo número de alumnado con nivel de conocimientos musicales (cluster 3).
El establecimiento de diferentes niveles de aprendizaje permite desarrollar actividades de aprendizaje adaptadas con diferentes niveles de dificultad y adaptadas a las necesidades particulares, intereses y motivaciones del alumnado.
El estudio realizado posibilita monitorizar la realización de test de evaluación inicial, en cuanto a su cumplimentación y realización del mismo, en cualquier momento a lo largo de la investigación. El empleo de las técnicas del Big Data aplicadas a los datos en educación posibilita tener un alto grado de control de los datos recogidos y hacer todo tipo de adaptaciones en tiempo real, aumentando así la versatilidad y la funcionalidad del programa. Dichas adaptaciones se realizan tanto en los procesos de recogida de información como en su posterior análisis de resultados obtenidos.
A partir de la naturaleza o tipología de los datos recogidos, los proyectos de análisis de datos educativos basados en el Big Data permiten redefinir los modelos utilizados, ya sean de exploración, descriptivos, de clasificación y predictivos. Se ofrece, así, un amplio abanico de posibilidades de análisis y monitorización de la información.
El empleo del Big Data en los cursos masivos en línea, cursos destinados a un elevado número de estudiantes, permite de manera rápida y personalizada adaptar los procesos de análisis de datos educativos para tomar decisiones educativas, adecuadas a los diferentes niveles de aprendizaje en el aula. Estableciendo itinerarios de aprendizaje, a partir de los estilos de navegación vía web y las estrategias de aprendizaje, así como las medidas de atención educativa eficaces y adaptadas a las necesidades tanto individuales como colectivas del alumnado en el marco de un aula inclusiva.
Las técnicas del Big Data presentan un alto nivel de idoneidad para el trabajo con cursos masivos en línea. Su enorme versatilidad, flexibilidad y potencia a la hora de trabajar con grandes volúmenes de datos las convierten en un recurso útil y eficiente, al servicio de la investigación educativa y el estudio de los procesos de enseñanza-aprendizaje online.
El modelo hallado, dada su fiabilidad del 100%, supone que es escalable e, independientemente del tamaño muestral, se puede aplicar a un sistema de análisis automatizado. Así mismo, es reproducible y repetible, es decir, permite ser aplicado a otros contextos de investigación en los que haya que clasificar la información del alumnado en perfiles de rendimiento académico.
En definitiva, el empleo de técnicas estadísticas avanzadas y análisis automatizados, procedentes del Big Data (bietápico, modelos clusters o de conglomerado) aplicadas a los procesos de enseñanza-aprendizaje musical online, presenta una forma eficaz, útil y novedosa, así como objetiva de establecer los niveles de aprendizaje, promoviendo la educación personalizada y la atención a la diversidad del alumnado.