









 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO  uBio
uBio 
 Permalink
PermalinkIntroducción
El progreso en la investigación biomédica se encuentra cada vez más impulsado por la información obtenida a través del análisis y la interpretación de conjuntos de datos grandes y complejos. A medida que la capacidad de generar y probar hipótesis a través tecnologías de alto rendimiento se ha vuelto técnicamente más factible e incluso más común, el desafío de obtener conocimientos útiles ha pasado de la mesada de laboratorio a la inclusión de la informática.
El presente trabajo es una adaptación del artículo “Cloud computing applications for biomedical science: A perspective” Navale & Bourne, 2018), publicado bajo la licencia de CC0 1.0 Universal (Creative Commons, 2020), el cual ofrece una lista de herramientas de computación en la nube útiles para académicos, investigadores y estudiantes de ciencias que trabajan con datos biológicos. Se realizó la presente adaptación con la intención de disponibilizar en habla hispana las principales posibilidades de la computación en la nube, actualmente accesible por la amplia adopción y el aumento de las capacidades de Internet, e impulsada por las necesidades del mercado. Estas herramientas han surgido como un enfoque poderoso, flexible y escalable para resolver problemas computacionales y de datos en las más diversas áreas de la investigación en biociencias.
El Instituto Nacional de Estándares y Tecnología (NIST, National Institute of Standards and Technology en inglés) clasifica las nubes en cuatro tipos: públicas, privadas, comunitarias e híbridas.
En una nube pública, la infraestructura existe en las instalaciones del proveedor de computación en la nube y es gestionada por éste, mientras que en una nube privada, la infraestructura puede existir dentro o fuera de las instalaciones del proveedor de computación en la nube, pero es gestionada por la organización privada. Ejemplos de nubes públicas incluyen Amazon Web Services (AWS), Google Cloud Platform (GCP) y Microsoft Azure.
Una comunidad en la nube es un esfuerzo de colaboración donde la infraestructura es compartida entre varias organizaciones una comunidad específica que tienen requisitos comunes de seguridad y cumplimiento de normas. La nube JetStream (Indiana University Pervasive Technology Institute, 2019) sirve como una nube comunitaria al servicio de la comunidad científica. Una nube híbrida es una composición de dos o más infraestructuras de nube distintas privadas, comunitarias, públicas que siguen siendo entidades únicas, pero que están unidas entre sí de forma que permiten la portabilidad de datos y aplicaciones de software (Mell & Grance, 2011).
Los tipos de nube mencionados anteriormente pueden utilizar uno o más servicios de nube: software como servicio (SaaS), plataforma como servicio (PaaS) e infraestructura como servicio (IaaS). SaaS permite al consumidor utilizar las aplicaciones del proveedor de computación en la nube (por ejemplo, Google Docs) que se ejecutan en la infraestructura de un proveedor de computación en la nube, mientras que PaaS permite a los consumidores crear o adquirir aplicaciones y herramientas e implementarlas en la infraestructura del proveedor de computación en la nube. IaaS permite al consumidor proporcionar procesamiento, almacenamiento, redes y otros recursos informáticos fundamentales.
Adopción de la nube para el trabajo biomédico
Considere ejemplos de cómo se han implementado las nubes y los servicios en la nube en biomedicina (Tabla 1) Sólo en genómica, el uso abarca desde aplicaciones individuales hasta máquinas virtuales completas con múltiples aplicaciones.
Herramientas individuales
BLAST (Camacho et al., 2009) es una de las herramientas más utilizadas en la investigación bioinformática. Una imagen del servidor BLAST se puede alojar en nubes públicas AWS, Azure y GCP para permitir que los usuarios realicen búsquedas independientes con BLAST. Los usuarios también pueden enviar búsquedas utilizando BLAST a través de la interfaz de programación de aplicaciones o (API, application programming interface en inglés) del Centro Nacional de Información Biotecnológica (NCBI, National Center for Biotechnology Information) de los Estados Unidos para que se ejecuten en AWS y Google Compute Engine (NCBI, 2019b). Además, la plataforma Microsoft Azure se puede aprovechar para ejecutar grandes tareas de correspondencia de secuencias BLAST dentro de límites de tiempo razonables. Azure permite a los usuarios descargar bases de datos de secuencias de NCBI, ejecutar diferentes programas BLAST en una entrada específica contra las bases de datos de secuencias, y generar visualizaciones de los resultados para facilitar el análisis. Azure también proporciona una manera de crear una interfaz de usuario basada en web, para programar y rastrear las tareas de BLAST, visualizar resultados, administrar usuarios y realizar tareas básicas (NCBI, 2019a).
CloudAligner es una herramienta rápida y completa, basada en MapReduce para mapeo de secuencias, diseñada para poder manejar secuencias largas (Nguyen, Shi, & Ruden, 2011), mientras que CloudBurst (Schatz, 2009) puede proporcionar un mapeo de lectura corta altamente sensible con MapReduce.
Tabla 1 (comienzo). Ejemplos de tipos de nube, modelos de servicio, flujos de trabajo y plataformas para aplicaciones biomédicas.
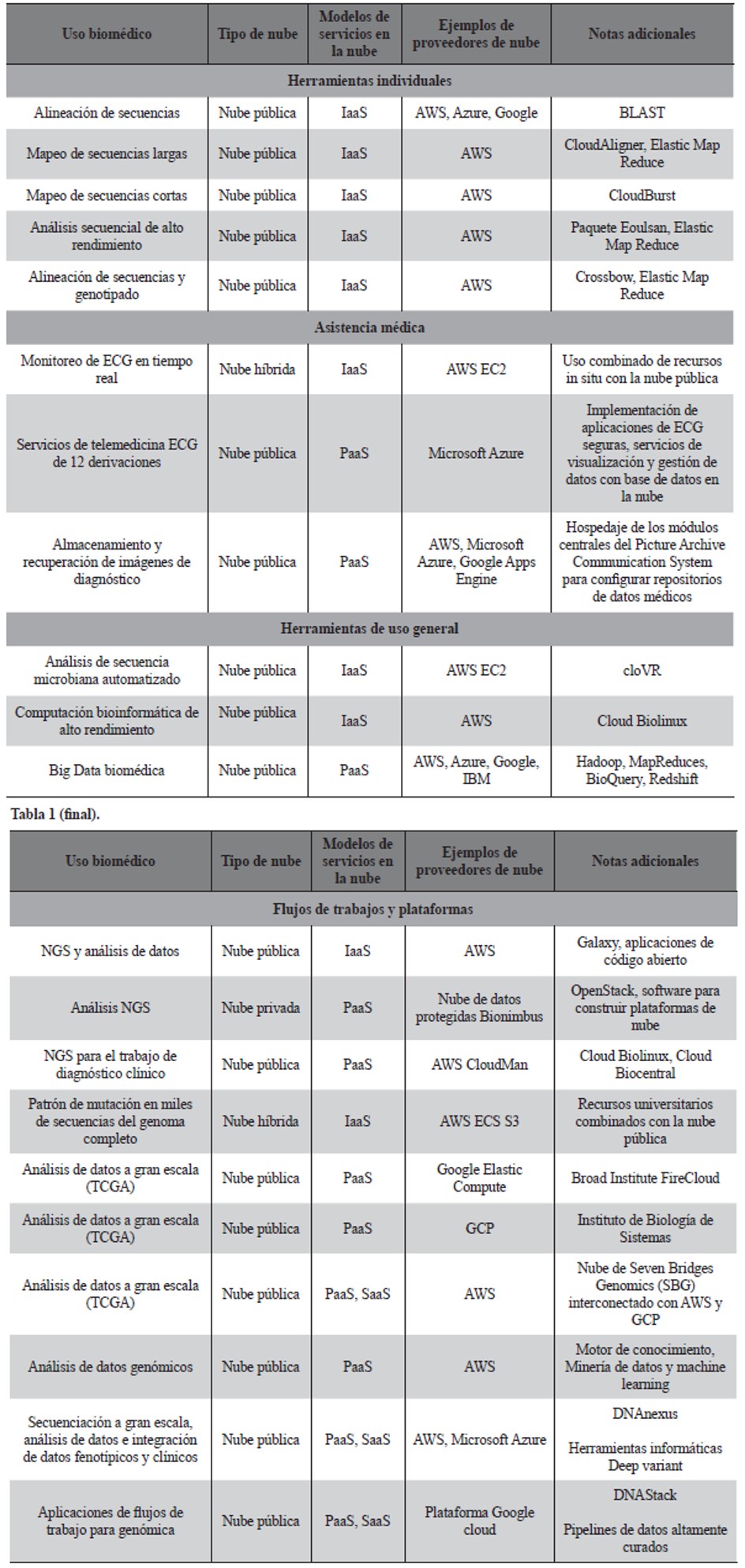
Abreviaciones: NGS) Secuenciación de nueva generación, AWS) Servicios web de Amazon, EC2) Nube de cálculo elástica, S3) Servicio simple de almacenamiento, TCGA) Atlas del genoma del cáncer, GCP) Plataformas de nube de google, IaaS) Infraestructura como servicio, PaaS) Plataforma como servicio, SaaS) Software como servicio.
El paquete Eoulsan integrado en un entorno IaaaS de nube permite realizar análisis de secuencias de alto rendimiento (Jourdren, Bernard, Dillies, & Le Crom, 2012). Para los análisis de resecuenciación de genoma completo, Crossbow (Langmead, Schatz, Lin, Pop, & Salzberg, 2009) es un pipeline de software escalable. Crossbow combina Bowtie, un alineador de lectura corta ultrarrápido y eficiente en memoria, y SoapSNP, un genotipador, en pipeline paralelo automático que puede correr en la nube.
Flujos de trabajo y plataformas
La integración de genotipo, fenotipo y datos clínicos es muy importante para la investigación biomédica. Las plataformas biomédicas pueden proporcionar un entorno para establecer un conducto de extremo a extremo para la adquisición, el almacenamiento y el análisis de datos.
Galaxy, una plataforma de código abierto basada en la web, se utiliza para la investigación biomédica con una gran cantidad de datos (Afgan et al., 2016). Para el análisis de datos a gran escala, Galaxy puede alojarse en la nube IaaS (Taylor, 2017). Se han logrado sistemas de flujo de trabajo fiables y alta- mente escalables basados en la nube para análisis de secuencias de próxima generación mediante la integración del sistema de flujo de trabajo Galaxy con GlobusProvision (Liu et al., 2014).
La Nube de Datos Protegida Bionimbus (BPDC, Bionimbus Protected Data Cloud en inglés) es una infraestructura privada basada en la nube para gestionar, analizar y compartir grandes cantidades de datos genómicos y fenotípicos en un entorno seguro, que se ha utilizado para estudios de fusión de genes (Heath et al., 2014). BPDC se basa principalmente en OpenStack, un software de código abierto que proporciona herramientas para construir plataformas en la nube (OpenStack, 2017), con un portal de servicio para un único punto de entrada y un único inicio de sesión para varios recursos disponibles de BPDC. Utilizando BPDC, el análisis de datos para el proyecto de resecuenciación de la leucemia mieloide aguda (LMA) se realizó rápidamente para identificar variantes somáticas expresadas en muestras primarias de alto riesgo de LMA (McNerney et al., 2013).
Se necesita una infraestructura escalable y robusta para los análisis de secuenciación de nueva generación o (NGS, Next Generation Sequencing en inglés) diagnóstico en los laboratorios clínicos. CloudMan está disponible en la infraestructura de nube de AWS (Afgan et al., 2010). Se ha utilizado como plataforma para la distribución de herramientas, datos y análisis de resultados. Las mejoras en el uso de CloudMan para el análisis de variantes genéticas se han realizado mediante la reducción de los costes de almacenamiento para análisis clínicos (Onsongo et al., 2014).
Como parte del Pan Cancer Analysis of Whole Genomes (PCAWG), se estudiaron patrones comunes de mutación en más de 2800 secuencias del genoma completo del cáncer, lo que requirió importantes recursos de computación científica para investigar el papel de las regiones no codificantes del genoma del cáncer y para comparar los genomas de células tumorales y normales (ICGC, 2017b). El centro de coordinación de datos del PCAWG cuenta actualmente con acuerdos de colaboración con el proveedor de nube AWS y el Cancer Collaboratory (ICGC, 2017a), un recurso académico de computación en nube mantenido por el Ontario Institute for Cancer Research y alojado en las instalaciones de Compute Canada.
Se utilizaron múltiples recursos académicos para completar el análisis de 1827 muestras en un período de 6 meses. Esto se complementó con el uso de recursos de la nube, donde 500 muestras fueron analizadas por AWS en 6 semanas (Stein, Knoppers, Campbell, Getz, & Korbel, 2015); lo cual demostró que los recursos públicos de la nube pueden ser utilizados para escalar de forma rápida un proyecto si se necesitan mayores recursos de computación.
En este caso, se utilizó el almacenamiento de datos AWS S3 para escalar de 600 terabytes a múltiples PBs. Las lecturas brutas, las alineaciones del genoma, los metadatos y los datos curados también se pueden cargar de forma incremental en AWS S3 para que la comunidad de investigadores del cáncer pueda acceder rápidamente a ellos. Las herramientas de búsqueda de datos y acceso también están disponibles para que otros investigadores las utilicen o reutilicen.
El Instituto Nacional del Cáncer (NCI, National Cancer Institute en inglés), ha financiado tres nubes piloto para proporcionar análisis genómicos, apoyo computacional y capacidades de acceso a los datos del Atlas del Genoma del Cáncer (TCGA, The Cancer Genome Atlas en inglés) (NCI, 2017). ISBobjetivo de los proyectos piloto fue desarrollar una plataforma escalable para facilitar la colaboración en la investigación y la reutilización de datos. Las tres nubes piloto han recibido conjuntos de datos de referencia armonizados del genoma del cáncer del Genomic Data Commons (GDC) (Grossman et al., 2016) que han sido analizados con un conjunto común de flujos de trabajo contra un genoma de referencia (por ejemplo, GRCh38).
El proyecto piloto del Broad Institute desarrolló FireCloud (Broad Institute, 2017a), utilizando la capacidad de cálculo elástica de Google Cloud para el análisis, la conservación, el almacenamiento y el uso compartido de datos a gran escala. Los usuarios también pueden cargar sus propios métodos de análisis y datos a espacios de trabajo y/o utilizar las herramientas del Broad Institute. FireCloud utiliza el Workflow Description Language (WDL) para permitir a los usuarios la ejecución de flujos de trabajo escalables y reproducibles (Broad Institute, 2017b).
El programa piloto del Instituto para la Biología de Sistemas o (ISB, Institute for Systems Biology en inglés) aprovecha varios servicios en la plataforma GCP. Los investigadores pueden utilizar aplicaciones de software basadas en la web para definir y comparar cohortes de forma interactiva, examinar los datos moleculares subyacentes para genes específicos o vías de interés, compartir puntos de vista con colaboradores y aplicar sus programas y scripts de software individuales a varios conjuntos de datos (ISB, 2017).
El ISB Cancer Genome Cloud (CGC) ha cargado datos procesados y metadatos del proyecto TCGA en el servicio de base de datos gestionado de BigQuery, lo que permite una fácil extracción de datos y enfoques de almacenamiento de datos que se pueden utilizar en datos genómicos a gran escala. El Seven Bridges Genomics (SBG) CGC ofrece tanto genómica SaaS como PaaS y utiliza AWS (Seven Bridges Genomics, 2017). La plataforma también permite que los investigadores colaboren en el análisis de grandes conjuntos de datos de genómica del cáncer de forma segura, reproducible y escalable.
Las plataformas comerciales (AWS, Microsoft Azure) basadas en la nube (por ejemplo, DNA-nexus) permiten el análisis de cantidades masivas de datos de secuenciación integrados con información fenotípica o clínica (Anderson, 2017). Otras plataformas bioinformáticas (por ejemplo, DNAstack) utilizan la GCP para proporcionar capacidad de procesamiento para más de un cuarto de millón de secuencias completas del genoma humano al año (DNAstack, 2017).
Asistencia de salud
Las aplicaciones de computación en la nube en la atención sanitaria incluyen la telemedicina/tele- consulta, las imágenes médicas, la salud pública, la autogestión del paciente, la gestión hospitalaria y los sistemas de información, la terapia y el uso secundario de los datos.
Un ejemplo conmovedor son los pacientes que sufren de arritmias cardíacas y requieren detección y monitoreo continuo de episodios. Los sensores portátiles se pueden utilizar para monitoreo de electrocardiograma (ECG) en tiempo real, detección de episodios de arritmia y clasificación. Utilizando AWS EC2, se integraron las tecnologías de computación móvil y se demostraron las capacidades de monitoreo de ECG para registrar, analizar y mostrar visualmente los datos de los pacientes en lugares remotos. Además, las herramientas de software que han monitorizado y analizado los datos de ECG se han puesto a disposición del público a través de la nube SaaS (Pandey, Voorsluys, Niu, Khandoker, & Buyya, 2012).
Herramientas de uso general
CloVR es una máquina virtual que emula un sistema informático, con bibliotecasy paquetes preinstalados para el análisis de datos biológicos (Angiuoli et al., 2011). De forma similar, Cloud BioLinux es un recurso público disponible con imágenes de máquinas virtuales y proporciona más de 100 paquetes de software para computación bioinformática de alto rendimiento (Krampis et al., 2012). Ambas imágenes de máquina virtual (CloVR y BioLinux) están disponibles para su uso en un entorno de IaaS en la nube.
La adopción de la nube también puede incluir servicios gestionados diseñados para problemas generales de Big Data. Por ejemplo, cada uno de los principales proveedores de nube pública ofrece un conjunto de servicios para aprendizaje de máquina e inteligencia artificial, algunos de los cuales se encuentran pre-entrenados para resolver problemas comunes (por ejemplo, texto a voz).
Los sistemas de bases de datos como Google BigQuery (Google, 2012) y Amazon Redshift (Amazon, 2016) combinan la naturaleza escalable y elástica de la nube con soluciones de software y hardware ajustadas para ofrecer capacidades y rendimiento de bases de datos que de otro modo no serían fáciles de conseguir. Para conjuntos de datos biomédicos grandes y complejos, estas bases de datos pueden reducir los costes de gestión, facilitar la adopción de la base de datos y facilitar el análisis. Varias de las grandes aplicaciones de datos utilizadas en la investigación biomédica, como la biblioteca de software Apache Hadoop, están basadas en la nube (Luo, Wu, Gopukumar, & Zhao, 2016).
Desarrollo de un ecosistema digital basado en la nube para la investigación biomédica
Los ejemplos presentados más arriba, algunos todavía en proceso desde hace varios años, ilustran una desviación del enfoque tradicional a la computación biomédica. El enfoque tradicional ha sido descargar datos a sistemas informáticos locales desde sitios públicos y luego realizar el procesamiento, análisis y visualización de datos localmente. El tiempo de descarga, el costo y la redundancia necesarios para mejorar las capacidades informáticas locales a fin de satisfacer las necesidades de investigación biomédica de gran cantidad de datos (por ejemplo, en secuenciación e imágenes) hacen que este enfoque merezca reevaluación.
Los proyectos a gran escala, como el PCAWG presentado anteriormente, han demostrado la ventaja de utilizar recursos, tanto locales como públicos, de varias instituciones colaboradoras. Para las instituciones con infraestructura local establecida (por ejemplo, infraestructura de red de alta velocidad, repositorios de datos seguros), desarrollar un ecosistema digital basado en la nube con opciones para aprovechar cualquiera de los tipos de nube (pública, híbrida) puede ser ventajoso. Además, el desarrollo y la utilización de un ecosistema basado en la nube aumentan la probabilidad de una ciencia abierta.
Para promover el descubrimiento del conocimiento y la innovación, los datos y análisis abiertos deben ser localizables, accesibles, interoperables y reutilizables (Findable, Accessible, Interoperable, and Reusable o FAIR, por sus siglas en inglés). Los principios FAIR sirven de guía a los productores, administradores y difusores de datos para mejorar su reutilización, incluyendo algoritmos, herramientas y flujos de trabajo que son esenciales para una buena gestión del ciclo de vida de los datos (Wilkinson et al., 2016). Un ecosistema de datos biomédicos debe tener capacidad para indexar datos, metadatos, software y otros objetos digitales, un sello de la iniciativa Big Data to Knowledge (BD2K) del NIH (Jagodnik et al., 2017).
La adopción de los principios FAIR se ve facilitada por un paradigma emergente para la ejecución de conjuntos de herramientas de software complejos e interrelacionados, como los que se utilizan en el procesamiento de datos genómicos, e implican empaquetar software utilizando tecnologías de contenedores Linux, como Docker, y luego orquestar pipelines utilizando lenguajes de flujo de trabajo específicos del dominio, como WDL y Common Workflow Language (Amstutz et al., 2016). Los proveedores de computación en la nube también ofrecen funciones de procesamiento por lotes (por ejemplo, AWS Batch) que proporcionan automáticamente la cantidad óptima y el tipo de recursos de cálculo basado en el volumen y los requisitos específicos de recursos de los lotes de trabajo enviados, lo que facilita considerablemente el análisis a escala. En la Figura 1 se ilustra la integración de productores, consumidores y repositorios de datos a través de una plataforma basada en la nube para apoyar los principios FAIR.
Es importante un programa de entrenamiento de forma regular para los usuarios de datos de la nube, especialmente para el manejo de datos sensibles (por ejemplo, información de identificación personal).
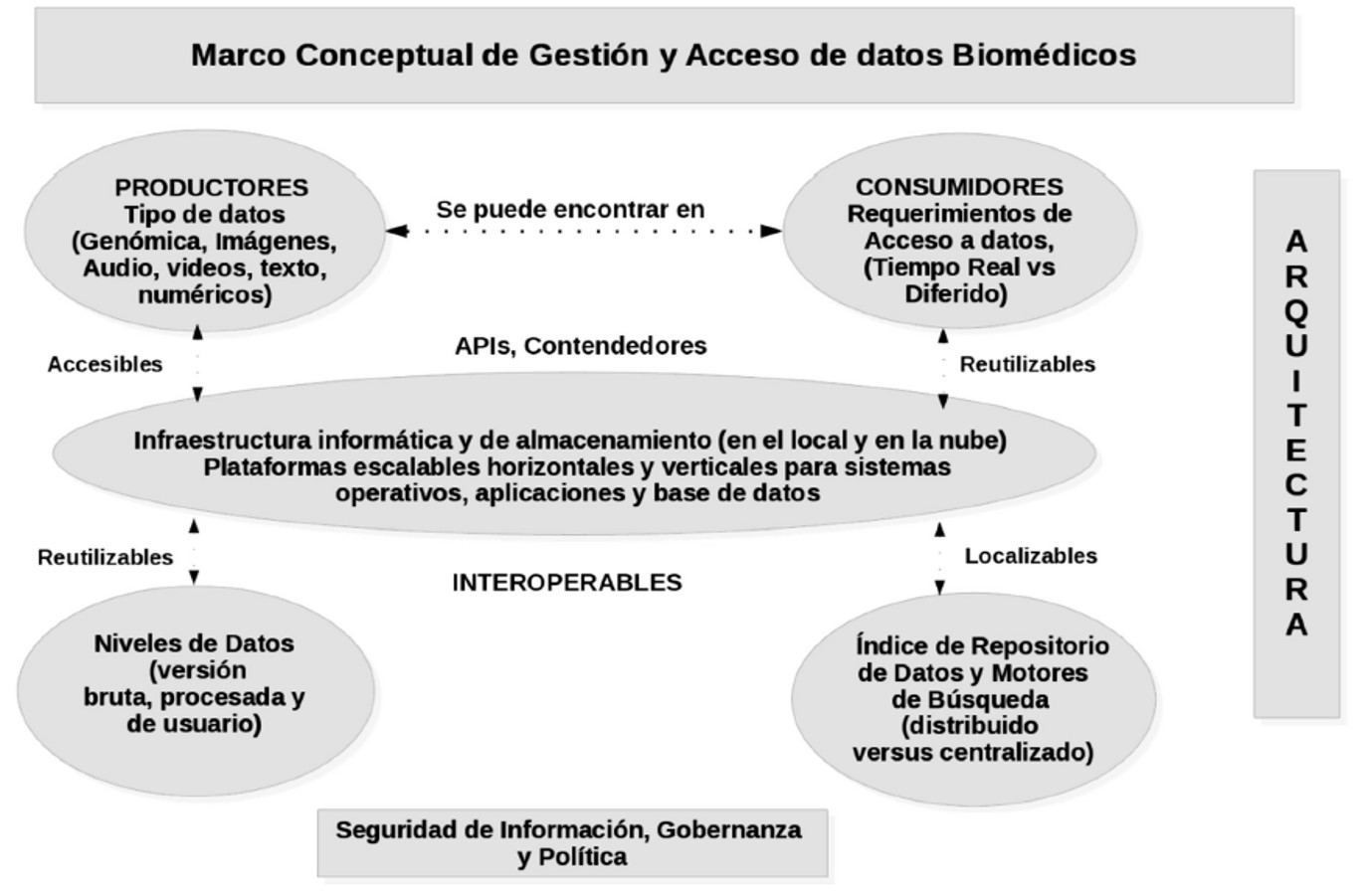
Figura 1 Plataforma conceptual basada en la nube con diferentes tipos de datos que fluyen entre productores y consumidores que requieren niveles de datos variables.
El entrenamiento debe incluir métodos para proteger los datos que se mueven a la nube y controlar el acceso a los recursos de la nube, incluidas las máquinas virtuales, los contenedores y los servicios en la nube que intervienen en la gestión del ciclo de vida de los datos. Proteger las claves de acceso, utilizar autenticación multifactorial, crear listas de usuarios para la gestión de identidades y accesos con permisos controlados siguiendo el principio del mínimo privilegio configurado para realizar las acciones necesarias para los usuarios son algunas de las prácticas recomendadas que pueden minimizar las vulnerabilidades de seguridad que pueden surgir de usuarios inexpertos de la nube y/o de entidades externas maliciosas (Foster & Gannon, 2017).
La búsqueda de datos biomédicos abiertos ha motivado el interés en mejorar el acceso a los datos y, al mismo tiempo, mantener la seguridad y la privacidad. Por ejemplo, un concurso abierto a escala comunitaria para el desarrollo de nuevos métodos de protección de datos genómicos ha mostrado la viabilidad de la externalización segura de datos y la colaboración para el análisis de datos genómicos basados en la nube (Tang et al., 2016). Los resultados del trabajo demuestran que las técnicas criptográficas pueden apoyar el análisis comparativo público basado en la nube de los genomas humanos.
Trabajos recientes han mostrado que utilizando un modelo híbrido de implementación de la nube, el 50%-70% de la tarea de mapeo de lectura puede llevarse a cabo de forma precisa y eficiente en una nube pública (Popic & Batzoglou, 2017).
En resumen, un ecosistema basado en la nube requiere capacidad para la interoperabilidad entre nubes, el desarrollo de herramientas que puedan operar en múltiples entornos de nube y que puedan abordar los desafíos de la protección de datos, la privacidad y las restricciones legales impuestas por diferentes países (véase Molnár-Gábor, Lueck, Yak- neen, & Korbel, 2017 para un análisis relacionado con los datos genómicos).
Conclusiones
El uso de las nubes, desde el análisis genómico a gran escala, pasando por la monitorización remota de pacientes, hasta el diagnóstico molecular en laboratorios clínicos, tiene ventajas pero también inconvenientes potenciales. Un primer paso es determinar qué tipo de entorno de nube se adapta mejor a la aplicación y, a continuación, si representa una solución rentable. Esta introducción intenta indicar qué se debe considerar, cuáles son las opciones y qué aplicaciones que pueden servir de referencia para tomar la mejor decisión sobre cómo proceder ya están en uso.